IT automation is the use of software to perform repetitive IT tasks and processes with reduced human assistance—think provisioning, scheduled maintenance, standard remediation, and repeatable deployments.
This isn’t a “buy a tool and everything runs itself” pitch; it’s a strategic approach to shrinking busywork, reducing human error in repeatable tasks, and making operations more predictable as you scale.
Quick take (the non-fluffy version)
- Automate the boring, repeatable stuff first: user lifecycle, routine maintenance, standard incident runbooks.
- Integration beats centralization: you rarely replace every system; you coordinate them with workflows and middleware.
- Automation has blast radius: if it can change 1 server, it can change 1,000—so you need guardrails.
- Pick a pattern, then a tool: workflow automation, runbooks, and infrastructure as code solve different problems.
Dominant intent: what most teams really want
Most companies don’t “want automation” as a goal; they want fewer manual handoffs, fewer midnight firefights, and fewer one-off processes that only one person understands.
So the real question is: which parts of your IT work are repeatable and policy-driven enough to turn into a safe, auditable workflow?
What IT automation is (and isn’t)
IT automation (the useful definition)
At its simplest, automation is software doing repeatable tasks consistently—on a schedule, on an event trigger, or as part of a standard runbook.
If you want a clean, citation-friendly definition for internal docs, Red Hat’s explainer on what IT automation is matches how most modern ITOps teams use the term.
What it’s not
- It’s not “AI runs the department.” (Even great automation needs ownership, reviews, and rollback plans.)
- It’s not “one dashboard that replaces every tool.” (You’ll still have systems of record.)
- It’s not automatically cheaper. (You trade manual time for engineering + maintenance time.)
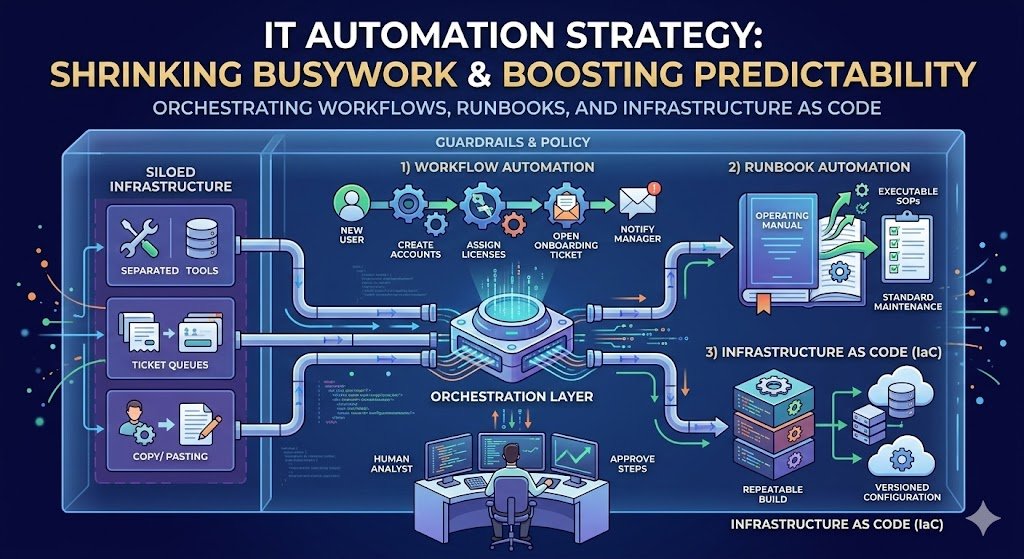
The real enemy: silos (aka tool sprawl with manual glue)
Most “siloed infrastructure” problems today aren’t about legacy hardware—they’re about disconnected SaaS tools, separate admin consoles, and ticket queues where humans do the copy/paste integration.
The fix usually isn’t ripping systems out; it’s adding an orchestration layer that can move data and actions between tools in a controlled way.
Middleware and workflow automation (the bridge concept)
Middleware is essentially “software glue” that enables connectivity between applications/components in distributed systems, so you don’t have to build a custom point-to-point integration every time.
That’s why the “middleware = webhook platform” phrasing is off: webhooks can be one mechanism inside an integration, but middleware is the broader category that connects systems and standardizes how they talk.
If you need a plain-language grounding for stakeholders, IBM’s definition of what middleware is is a solid reference.
The 3 automation patterns that matter (pick your lane)
1) Workflow automation (connect processes across tools)
This is “when X happens, do Y across systems”: new hire created → create accounts → assign licenses → open onboarding ticket → notify manager.
A common example of this category is Azure Logic Apps, which Microsoft describes as a platform to create and run automated workflows across enterprise ecosystems using prebuilt connectors.
If you want a representative reference for this pattern, use Microsoft’s overview of Azure Logic Apps.
2) Runbook automation (standard operating procedures, but executable)
Runbooks turn “the steps we always do” into scripts/workflows you can run consistently—manually with approvals, or automatically when triggers fire.
Microsoft’s documentation describes Azure Automation features like runbooks, schedules, modules, and hybrid runbook execution for non-Azure machines (Hybrid Runbook Worker).
For a concrete example of what runbook automation includes, see the Azure Automation overview.
3) Infrastructure as Code (IaC) (provisioning as a repeatable build)
IaC is how modern teams stop clicking through cloud consoles and start treating infrastructure changes like code changes: reviewable, versioned, repeatable.
HashiCorp describes Terraform as an infrastructure-as-code tool that lets you build, change, and version cloud and on-prem resources safely and efficiently via configuration files.
If you need a neutral citation for “what IaC looks like in practice,” use HashiCorp’s Terraform introduction.
What to automate first (a decision tree that actually works)
- Start with high-volume, low-judgment work: tasks with a clear “right answer” (onboarding/offboarding, password resets, scheduled maintenance).
- Automate where you can enforce policy: tagging, access reviews, ticket routing, standard patch windows.
- Prefer reversible actions first: if rollback is easy, it’s safer to automate earlier.
- Delay anything that needs human context: vague incidents, ambiguous approvals, or one-off exceptions.
Guardrails: how automation fails in the real world
- Credential and secret sprawl: automations need access; unmanaged secrets become your new weakest link.
- Silent partial failure: step 3 fails but step 4 still runs; your systems drift out of sync.
- Over-automation: you automate a broken process and just break it faster.
- No ownership: “the automation” becomes a zombie workflow nobody dares to touch.
Troubleshooting (symptom → likely cause → fix)
- Automation runs twice → duplicate triggers or retries → add idempotency checks and correlation IDs.
- Workflow runs but nothing changes → missing permissions/scopes → audit service accounts and least-privilege policies.
- Random failures → rate limits/timeouts → add backoff, queues, and clear error handling.
Implementation checklist (pilot-ready)
- Pick one process and document the “current state” steps and handoffs before you automate anything.
- Define success in operational terms (time saved, fewer tickets, fewer escalations, faster recovery).
- Build approvals into the risky steps (especially anything that changes access, deletes resources, or touches production).
- Log every action (who/what/when), and make failures noisy (alerts + tickets).
- Assign an owner and a change process for the automation itself (versioning, review, rollback).
FAQ
Is IT automation the same as DevOps?
Not exactly—DevOps is a way of working; automation is one set of techniques DevOps teams commonly use to make delivery and operations repeatable.
Do I need middleware to automate IT?
Not always, but as soon as you’re coordinating multiple systems, you’ll want a clear integration approach (often via middleware + workflows) rather than point-to-point scripts.
What’s the fastest “first win” for automation?
User lifecycle workflows (joiner/mover/leaver) and standard ticket/runbook tasks are usually the quickest wins because they’re repetitive and policy-driven.
Will automation reduce headcount?
Sometimes it reduces toil more than headcount: the common goal is freeing skilled staff for higher-value work rather than eliminating roles.
How do I keep automation from becoming a security risk?
Use least-privilege service accounts, keep secrets managed, require approvals for high-impact steps, and log everything so actions are auditable.
Should we automate before we standardize processes?
Standardize first whenever you can; automation tends to amplify whatever process you already have—good or bad.
What should we avoid automating early?
Avoid actions that are irreversible, poorly understood, or highly exception-driven until you have solid monitoring, approvals, and rollback plans.
Where should I go next on your site?
Good follow-ups are a runbook automation guide, an infrastructure as code basics explainer, and a workflow automation vs RPA comparison.
💬 Comments